Azure Stream Analytics - ultra-fast garbage ETL
Contents
Hi, here you’ll find some general thoughts about the ETL, and some special exercises solved with a pretty attractive option we can have with modern cloud providers - Azure in my case.
My example is a stream of values coming from some source, to keep it simple, let’s say we are receiving timestamp and value.
The stream is very dense, and we want to compress it in time and provide some other structure of payload (basically, just
transform it from one JSON format to another one).

I would say, that this is one of the fundamental things you usually do with your stream of data in ETLs. Either transforming its format 1 to 1, or making some manipulations with it before feeding it to the consumer.
Stupid questions and general thoughts
You may say: “Well, is this a problem, man? People solved it many times already.” For example, the old-fashioned staging approach:
- save data in the stage storage,
- make needed transformations,
- store it further in the next stage - prepared for the consumer.
Or even manipulate the data right at the place: update it, enrich, whatever…
Well, what if I tell you, that the stream itself is garbage, it’s needed no one. You’ll undoubtedly remove it just after calculating a bigger chunk (aggregate) of it.

Moreover, what if it’s a very overloaded, dense one? From hundreds of values, you’re compressing to only one - needed one.
Sorting garbage
To save resources (and probably some costs) we don’t want to save in storage something we actually don’t want to store. At the same time, we want to read, analyze and prepare some meaningful outcomes from it before throwing away. How can we do it?
Well, among many other ways of doing it, I think, the manipulations right on the stream (on the fly) might be a fascinating option.
And the Azure Stream Analytics is the right tool for that.
Indeed, it was created just exactly for the task we have - it can take a stream from input apply analytics, configured as an SQL query to it,
and send the result to the output.

What I am going to do is just configure workflow in Azure. The Azure Event Hub is going to be a source in my setup I would need to write some custom applications to send mock data to it. Also, I’ll create the Azure Stream Analytics query, which is going to listen for the stream in the Hub and send results to the Service Bus Topic. Fortunately, Service Bus has a nice explorer to easily pick and check the incoming messages - that’s the final destination of the experiment.
The Azure Stream Query
Ok, enough talking, let’s make hands dirty. Before configuring the stream query, we need to create the source and destination.
Create some random Event Hub and copy the connection string from its Shared access policies (we will need it later). Also
create some Service Bus topic, It might be a good idea to put everything in one Resource group for cleaning up all
together after finishing.
Now, let’s configure Azure Stream Analytics. The first thing you see is three main parts you need to configure
 As input, we are selecting created Event Hub
As input, we are selecting created Event Hub
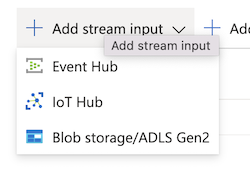
As output, way more options, but chose the Service Bus Topic this time

What we actually want to do is to write some kind of window aggregation. It has to aggregate seconds-resolution data
to minutes-one. For simplicity, we aggregate values into an array. Here how the Query might look like:
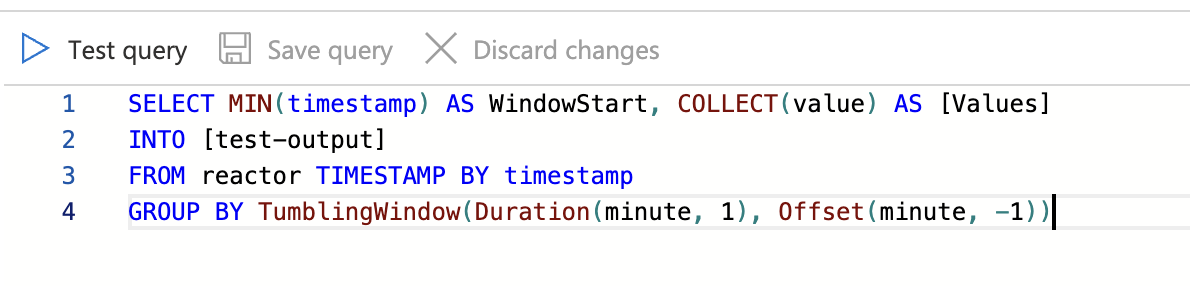
Reactor is the name of the input from Event Hub, and we are marking the field timestamp from the incoming payload as the data piece
responsible for the timeline. TumblingWindow
is just a bucketing function for time - we are cutting it by minutes.
Looks simple, right? Also, there is a nice feature, that you can run a test query on the data in your Event Hub, before saving the query. Not forgetting to start the Stream Analytics Job.
The Source
Next, I am going to send every second event with the payload of this structure to the newly created Event Hub:
|
|
In this GitHub repo you can find the application I am using for sending data. I took the default Azure SDK for communication with Event Hubs. For some time they actively support reactive stack in the SDK (Flux/Mono), so I’ll keep the trend and write the client in a reactive way.
Let’s send a bit of data:
|
|
Tada, the console should show something like:
|
|
The Output
Last but not least… Let’s check the results. All we need to do is to navigate to the Service Bus Explorer of the target Topic and pick some messages from it. Here is an example:
|
|
Nice. We got the aggregate data with minutes interval defining logic by SQL syntax, and a couple of clicks. I find it really convenient and cool. The SQL query in Azure Stream Analytics is quite powerful, there are many other functions for manipulating with the data. Besides, you can join the stream with some reference data from Blob storage or from SQL Database which makes it highly flexible. What do you think?

Conclusion
Ok, does this solution have any cons at all? Yes, of course. For example, there is bad support for local development. It provides a local environment for Microsoft family tools, like Visual Studio. And the SQL itself is not pure SQL syntax, so you won’t be able to mock it somehow with some other containerized database. So organization of the development life-cycle is not trivial for this solution.
Also, pricing for the service I would say a bit over-priced. It’s suggested to start at least from 6 streaming units (SU), but 1 SU = $0.12/hour, which makes it at least $ 80 per month. I can imagine this affordable solution for huge streams, where alternative solutions of similar efficiency will cost this money anyway.
Alternatively, you can try to build a simple application on your own and put it in some existing k8s infrastructure. Manage it resources more precisely, but you would need to pay for some storage anyway.
In the end, It’s very tempting to write just one SQL query instead of inventing the wheel - self - written solution with all the infrastructural concerns addressed. Every tool is good only for specific task conditions.
Author Relaximus
LastMod 2022-10-02